 |
A principal goal of high computational power architectures is to allow multiple instructions to be issued within a single clock cycle (multiple-issue). There are two main variations of multiprocessor, multiple-issue architectures - Very Long Instruction Word (VLIW) and superscalar. An often seen variant of the latter is known as the Multiple Instruction streams, Multiple Data streams (MIMD) architecture. Context technologists have implemented the most advantageous performance features of the superscalar and MIMD architectures within our DRL. It contains two major architectural innovations, an enhanced version of the Most Significant Digit First/Sweeney, Robertson, Tocher (MSDF/SRT) arithmetic processing algorithm and coarse-grained dynamic reconfigurability.
|
Enhanced
version of
MSDF/SRT |
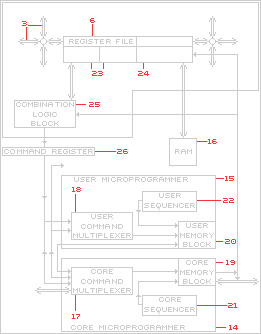
Our Arithmetic Processing Algorithm (APA) allows us to use a single, small logic block [Reconfigurable Processing Unit (RPU)] as illustrated in the following figure, which is taken directly from one of our early patents. It is important to note that the RPU's silicon implementation is advantageously derived straight from the "workings of" our APA. Within the RPU all operations may be performed bit-by-bit (fine-grained DRL is thus achieved when necessary via software), beginning with the most significant bits of the operand and produce the resultant in the same manner, that is the Most Significant Digit (bit) First.
This logic operational process features:
- use of the most significant resultant bits in the next operation while the less significant bits are still being calculated in the initial operation. We call this benefit ultrascalar calculation.
- calculations of any operand may be terminated when any pre-specified degree of calculational precision is achieved. We call this benefit variable precision (independent developers claim a 37% improvement in total execution times using this feature alone) 1. Variable precision enables the use of floating point operations with virtually the same cost, footprint and power consumption Si parameters as are used for fixed point operations.
|
|
Context RPU
- Tying
The Silicon
To The Math |
 |
|
Dynamic
Reconfiguration |
The five principal market drivers which the Context DRL addresses are (1) maximum computational power at the highest computational silicon efficiency, (2) minimum power dissipation, i.e. minimize milliWatts consumed for the processing of all algorithms within the domain, (3) minimum area required, (4) maximum flexibility in order to reduce NRE and times-to-market and to best accommodate new "killer apps" and changing standards in the field and (5) maximum code densities so as to minimize memory requirements and reduce latencies. Coarse-grained, dynamically reconfigurable architectures have been shown in many applications/domains (across multiple algorithms) "to produce at least one order of magnitude in power reduction and increase in performance." 2
Our RPUs are coarse-grained dynamically reconfigurable and thereby enable dynamic context switching of their logic blocks in space and time, so that they operate in time-sharing, architecturally optimized states. To be most highly effective, DRL must (and Context DRL does!) have the ability to
- provide fast random access to co-located configuration [Target Architecture (TA) and Instruction Set Description (ISD)] memory.
- perform fast (preferably within four cycle counts), complete context switching.
- use a coarse-grained architecture to (a) avoid the reconfiguration overhead attendant to fine-grained architectures and (b) so that it is better suited for application implementation of computational tasks from a high-level programming language and/or similar sources.
|
|
Software
Development
Tools |
Our tool development is outsourced to DSP Design Automation (DSP-DA), a fully owned subsidiary of Soft. Networks, LLC, Atlanta, Georgia, whose principals include leading compiler experts, such as Dr. Vijay Madisetti, CEO of Soft. Networks and Professor, ECE, at Georgia Tech. These tools include the compiler, assembler, linker, profiler and debugger. The Context software simulator has already been developed and successfully applied in a major wireless benchmark competitive study.
|

1 Bondalapati, Kiran, et al, "Dynamic Precision Management for Loop Computations on Reconfigurable Architectures," IEEE Symposium on Field-Programming Custom Computing Machines, April 1999. /back/
2 Alsolaim, Ahmad, et al, "Architecture and Application of a Dynamically Reconfigurable Hardware Array for Future Mobile Communication Systems," 2000 IEEE Symposium on Field-Programmable Custom Computing Machine, April 17-19, 2000, Napa, CA, p. 206 /back/
|
|


